Transformer模型
一种新颖的序列到序列模型,可以解决各种自然语言处理任务,如机器翻译、文本摘要、情感分析等。
transformer模型有两个大部分:Encoders和Decoders。Google根据Encoders提出了BERT模型,OpenAI根据Decoders提出了GPT-1。
NLP自然语言处理
BERT
基于Transformer模型的一种前向和后向预训练语言模型,可以用于多种NLP任务,如文本分类、命名实体识别、问答等。
PyTorch
Pytorch是torch的python版本,是由Facebook开源的神经网络框架。
pytorch安装及使用GPU失败的解决办法_pytorch用不了gpu-CSDN博客
Tokenizer
Tokenizer是一个用于向量化文本,将文本转换为序列的类。
深度学习文本预处理利器:Tokenizer详解-CSDN博客
Bert的文本编码tokenizer、分隔符(MASK/CLS/SEP)编码_bert编码-CSDN博客
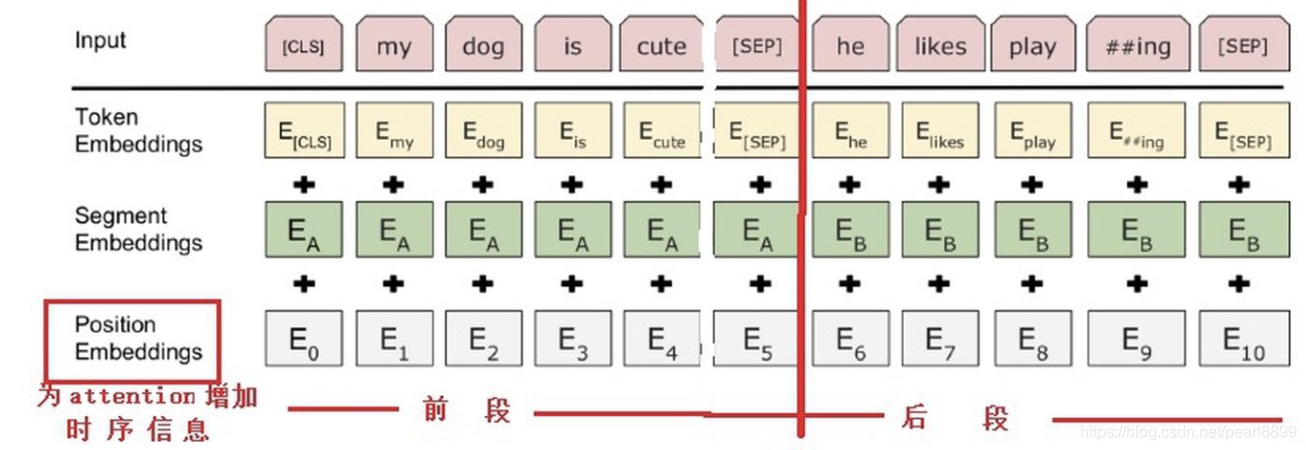
BERT模型的输入是文本,需要将其编码为模型计算机语言能识别的编码。
预训练和微调
手头任务的训练集数据量较少,先把好用的大模型的大量参数通过大的训练集合预训练。
接下来再通过手头上少的可怜的数据去Fine-tuning(即微调参数),以更适合解决当前的任务。
余弦相似度
- 我们可以将人和事物表示为代数向量
- 我们可以很容易地计算出相似向量之间的相互关系。
词嵌入
例如GloVe向量
N-gram模型和神经网络语言模型(NNLM)
预测/提示下一个单词。
N-gram模型当前词只与距离它比较近的n个词更加相关(一般n不超过5,所以局限性很大)。
NNLM的核心是一个多层感知机(Multi-Layer Perceptron,简称MLP)
嵌入矩阵
Word2Vec
【图文并茂】通过实例理解word2vec之Skip-gram-腾讯云开发者社区-腾讯云 (tencent.com)
Word2Vec主要实现方法是Skip-gram和CBO。
CBOW的目标是根据上下文来预测当前词的概率。
Skip-gram刚好相反,其是根据当前词来预测上下文概率的。
连续词袋模型CBOW
连续词袋模型(CBOW) - emanlee - 博客园 (cnblogs.com)
它是一种用于生成词向量的神经网络模型。
CBOW的基本思想是,给定一个单词的上下文(即窗口内的其他单词),预测该单词本身。
Skip-gram 模型
负采样
基于一定的策略构造与正例相对的负例的过程,称为负采样 (Negative Sampling) 。
